PySMS


I'm in Python every day at this point, and since I work with mathematicians, it also happens to be their go-to. Its dynamic, interactive nature lets us rapidly write code that actualizes the research done by our senior engineers. Not to mention, it gets first-class attention from the ML/AI community, so all the latest PyTorch models and cutting edge research make their way to Python first.
Inception
I began to notice a pattern among the number of projects we've been working on. We were constantly rewriting the same utility functions, creating a fair amount of code duplication.
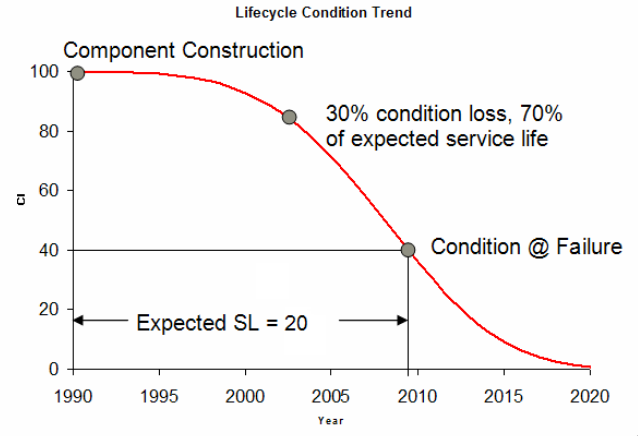
A large chunk of our work revolves around facility degredation simulation, which itself revolves around particular statistical models like the Weibull Curve (seen below).
Take for example, this set of PyTorch functions authored by one of our mathematicians for a facility optimization project:
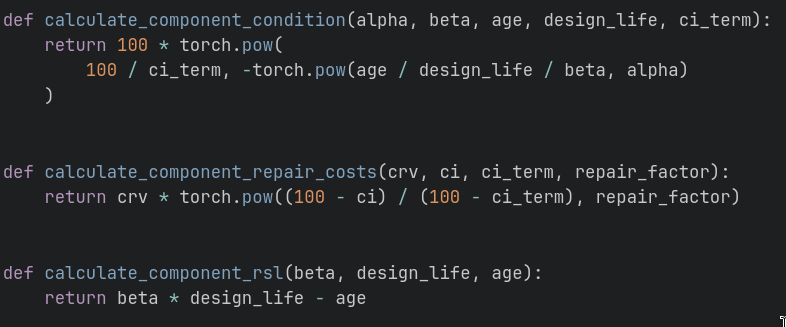
Don't worry if its not obvious what these functions do, as they are specific to our domain. The bottom line is that these same calculations have been written a number of times, scattered across jupyter notebooks, .py files and even written in languages like C# and R (As an aside, the top function actually draws out the weibull curve in the picture above).
At some point late summer 2025, I thought it'd be useful if we had a place to put these common utilities. That way, we had one source of truth so we could create some thorough documentation and unit test the hell out of the code. So, I asked around if anyone thought it was remotely a good idea and not just a waste of time and precious taxpayer dollars. They were all onboard and thus, the PySMS repository was born.
Design
Throughout the project, I've tried to draw design inspiration from popular Python repos (ie. Requests, Scikit-Learn, Seaborn). Whether its the API, unit tests, CLI, or even the documentation, I wanted my project to follow some tried and true design patterns.
At a high-level, I've separated the library into two sections: the functional API and the object-oriented API. The functional API exposes the program in a way that looks similar to those functions from earlier. The Object-oriented approach is a bit more complex and has certainly tested my software engineering chops.
E-SMS manages DoD real property through a heirarchical categorization system. Organizations (ie. DoD, Army, Air Force) contain installations (forts and bases) which contain sites which contain facilities (also called "assets") which contain systems (ie. A10, B10 in the Uniformat standard) which contain components (think A/C units, doors, walls). This system lends itself well to being thought of in an "object-oriented" sense.
I went through a couple first drafts before getting fed up with how long it was taking and settled on a decent "good-enough" system which could be seamlessly integrated into other ongoing projects.
The E-SMS heirarchy is a tree whose leaf nodes are the Components. Each level in the heirarchy is composed of instances at the level directly under it. We call these instances "children". I chose to represent an entire collection of these objects as an ESMSPortfolio.
The ComponentSection (the canonical name for "component") does a lot of the heavy lifting in terms of pure computation. Essentially, our research-driven degredation models, like the Weibull Curve, are often at the component-section level. When inspectors come in, they look at individual components and give them a color rating (ie. green, amber, red) which maps onto a 0-100 scale where 40 signifies a failed component. This 0-100 value is known as the Condition Index (CI). Heirarchy levels above the component will often "roll-up" these metrics using weighted averages to get metrics at their level. For instance, to get Asset BCI (Building Condition Index), we'd take a weighted average of all the components' CI's multiplied by their replacement costs. The intuition is that more expensive components should have a greater effect on a facility's overall health. The goal is to be able to call asset.project_condition_index() which, under the hood, calls component.project_condition_index() on all of its components to calculate BCI.
But, we've run into an issue here. An asset never has just one component, so to calculate each component CI one would think to loop through every component and collect the values in a list. This scales horribly as our portfolio grows, since the Army manages millions of components across a large number of installations. This is where vectorization comes in, where we can escape the overhead of Python and utilize efficient algorithms written in C and C++.
I decided to use PyTorch Tensors as our primary backend container. Most of our projects use PyTorch for the neural nets and ML models we've built, and we usually ssh into a shared computer with 2 RTX 4090's, allowing us to use CUDA whenever we want to train said models.
Since analysis is only ever useful on multiple components, never just one, we must vectorize all of our data for efficient computation. So each heirarchy level has a corresponding Aggregation object consisting of one or more instances at that level, each with an attribute that refers to its child-level aggregation. For instance, an AssetAggregation has an attribute named components which refers to a ComponentAggregation instance. That way, a ComponentAggregation instance can hold all of its components' data in Torch Tensors. Then, projecting condition index on 100 million components takes a fraction of a second (under certain assumptions about hardware). This is efficient because our data is now columnar, as opposed to row-wise. Each attribute of each component is stored contiguously in memory.component_aggregation.alpha returns a tensor of alpha values akin to accessing a Pandas DataFrame's column.
The model API is a subset of the object-oriented API. I use Protocols to define models to take advantage of Python's duck-typing system. As of now, a model is any object with a .predict() method, but different types of models have predict methods with different function signatures. A WeibullCI model takes a ComponentAggregation and accesses its members accordingly. I'm hoping to improve this system in the future as our needs change and grow, and as I learn more about Scikit-Learn's model API.
Use Cases
I have to take a pragmatic approach when developing this library. If it doesn't work well with our existing workflows, no one is going to use it.
One particular use case is being able to parse familiar tables of E-SMS data into PySMS objects. I've began with pysms.read_csv() and pysms.read_parquet() which mirror the Pandas top-level functions. They each take in a filepath and parse the respective formats into an ESMSPortfolio which can access each level in the heirarchy through its properties (.assets, .components, etc.). It also has a .dataframe() method which performs joins on each levels' DataFrames. Because this is computationally expensive, the DataFrame is constructed only once the method is called. In an environment where performance is key, we usually won't call this. But, it's there!
Another reason for designing the object-oriented API is because there's a senior engineer on our team who has come to me with countless brilliant ideas of models he wants to test out and use. Instead of having to wait for me to understand his models which I feel require a PhD in engineering to understand, I want him to be able to implement them in a way that works seamlessly within PySMS.
Challenges
By far, the biggest challenge is finding the best way to parameterize functions and object constructors. For instance, calculate_component_condition() is technically a function of component age. Therefore, the function signature can require the user to pass the "component age" or... it can require "year built" along with a "projection_date" which defaults to datetime.now(). Adding insult to injury, function overloading is not native to the Python language.
Also, the heirarchy objects are intended to be intuitive containers of tabular data we pull from our inventory.
The PhD engineers on our team have a much better intuition for how these should look. It's also one of those things where there isn't a single right answer (but there are wrong ones). That's why this project is an iterative process and is still in active development.
Conclusion
This project was born out of a need to centralize and deduplicate common engineering and R&D utilities within the E-SMS ecosystem. It provides an avenue for members of our team to experiment and interact with our research findings in a tangible way. It also aims to speed up future development. Following SOLID principles and common design philosophies, PySMS is extensible and modifiable. My goal is that this project stands the test of time and is useful to us in a number of projects.